
Many of the services offered by Azure can be used to extend the capabilities and improve the efficiency Office 365. This is especially the case for SharePoint, both on-premises and in the cloud. One of the services offered by Azure is “Azure Batch”, which is a Platform as a Service (PaaS) solution that provides all the physical infrastructure plus the core software to run programs in groups, removing excessive server loads from production.
In Part One of this article, where we explored how Azure batch works, how it works with SharePoint and how to initiate this in your environment. In Part Two, we’ll be looking at the configuration of Azure Batch, its execution and the results the solution creates. The complete source code for the application can be found in the GitHub repository.
The Configuration of Azure Batch
Step 8 – The MainAsync routine is the principal entry point to create the Azure infrastructure. Here you need to start the batch process, gather the results, and send them back to SharePoint. This element of the task is asynchronous and takes care of the creation and decommissioning of the relevant Azure resources in a proactive way.
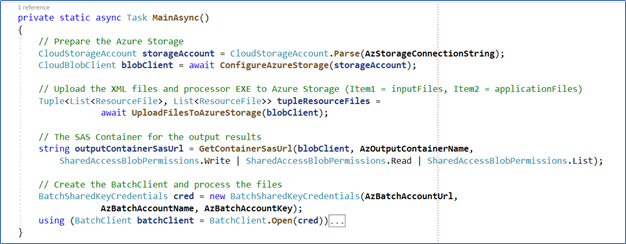
Figure 6. The principal part of the MainAsync method
Note: the batch operations (inside the “batchClient” object creation) are defined as:
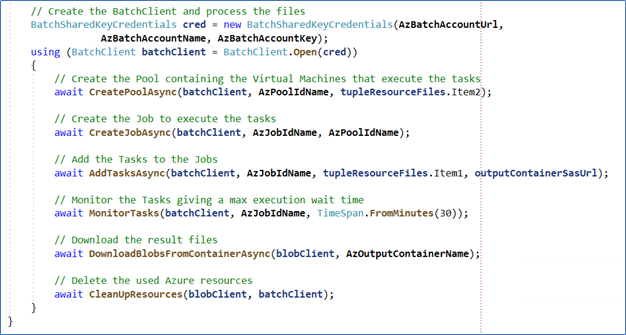
Figure 7. Definition of the Batch operations
Step 9 – The storageAccount variable contains a pointer to the Azure Storage using its connection string. The ConfigureAzureStorage routine creates all the necessary containers and blobs in the Azure Storage and returns a variable blobClient of type CloudBlobClient.
Here, you’ll create three blobs: one to contain the XML files from SharePoint, one for the executables that will process the XML files, and one for the results of the processing operation.
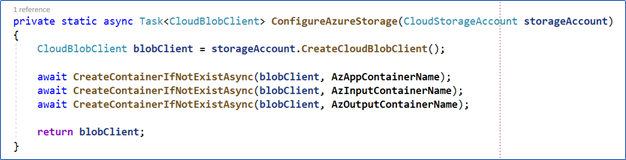
Figure 8. The Azure Storage Blob Containers are created dynamically
Step 10 – The “UploadFilesToAzureStorage” routine carries out two different tasks:
- It reads the XML files for each item in the SharePoint List and uploads them to the data file container
- It uploads the files of the executable CreatePdf.exe that will process the data (the code of this executable is explained at the end of the article). This routine returns a DotNet Tuple that contains two generic lists with objects of type ResourceFile containing references to each of the files uploaded to Storage
The first part of the routine loops through all the elements of the SharePoint List using the SharePoint Client Side Object Model. It then converts the attached XML file of each element to a stream, creates a generic list of Tuples that contains the element name and stream of the XML file, and uploads it to the Azure storage container. The second part is identical, but for the files of the processor.
Step 11 – To upload the files processed by the Batch, Azure needs the SAS (Shared Access Signature) of the output blob container to be used in Azure Storage. The SAS is calculated by the GetContainerSasUrl routine:
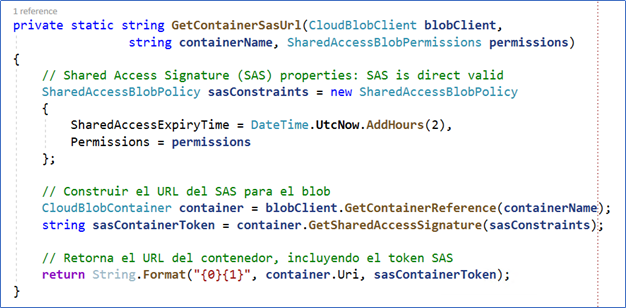
Figure 9. The calculation of the SAS for the output container
Step 12 – Initially, in the part corresponding to the creation of the infrastructure needed in Azure, the Pool that contains the processing Virtual Machines is created using the routine CreatePoolAsync:
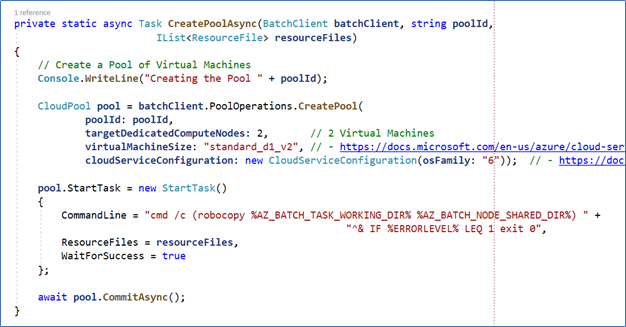
Figure 10. The creation of the Virtual Machines Pool
During the creation of the Pool, you need to specify how many nodes (Virtual Machines) are needed (two in the example), which type of machines (“standard_d1_v2” in the example, the list with possible values can be found in here) and the type of operating system (“6” in the example for Windows Server 2019; the list with values can be found in here).
It’s also possible modify the configuration, that is, if more power is needed, the Pool itself creates additional Virtual Machines. The Pool specifies a command that is executed when each Virtual Machine starts. In this case, it is indicating that two working variables must be created to contain the directories where the executables will be uploaded and where the working files are to be maintained.
Step 13 – Once we have the Pool, we need to create the Job that will contain the Tasks. This is done by the CreateJobAsync routine.
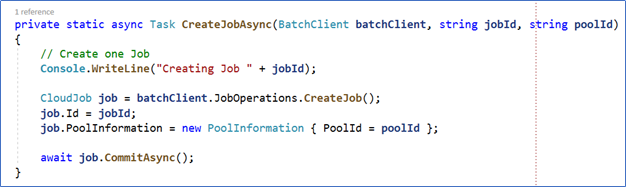
Figure 11. The creation of the Job
Step 14 – The AddTasksAsync method is responsible for creating the Tasks to be executed and started:
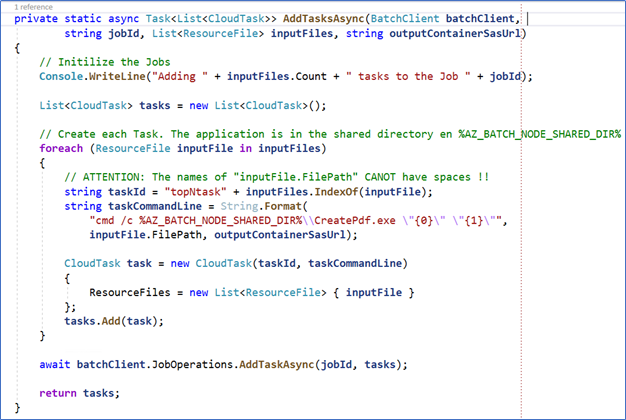
Figure 12. The creation of the Tasks
A Task must be defined for each data file that has been uploaded to the storage. One of these Tasks is a command that you need to run; for example, the command starts the CreatePdf.exe with two parameters: a specific data file, and the SAS of the Storage Output Blob.
Azure Batch distributes the Tasks across the available Virtual Machines, balancing the load between them. Finally, the JobOperations method starts the Azure Batch job, creates the Virtual Machines, downloads the executable and data files into them, and gives the command to start the job.
Step 15 – Tasks can be monitored when they are finished. The MonitorTasks routine defines the timeout as a parameter. If the timeout fires before any Task has finished, a message is displayed. Also, if a Task ends smoothly or with an error, the corresponding message is also displayed.
Step 16 – When the task finishes running, it uploads the result to the Azure Storage output blob. When all tasks are finished, the DownloadBlobsFromContainerAsync routine uploads the PDF files to the corresponding SharePoint List items using, again, the SharePoint Client Side Object Model.
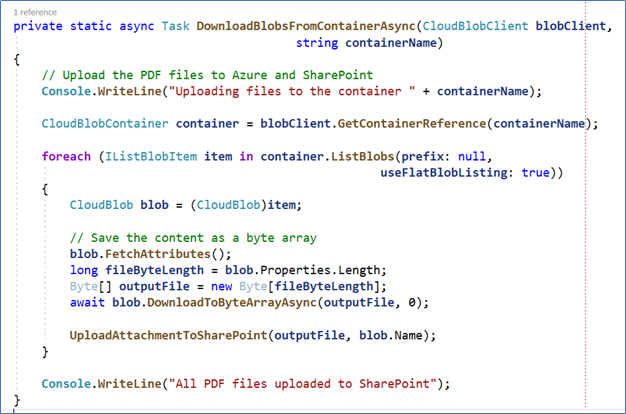
Figure 13. The results are uploaded to Azure and SharePoint
Step 17 – When the PDF files are uploaded to SharePoint, we do not need to keep the Azure Batch or Azure Storage infrastructure for longer (if the resources are up and running, you need to pay for them). To delete all those resources, the “CleanUpResources” function is called at the end of the process.
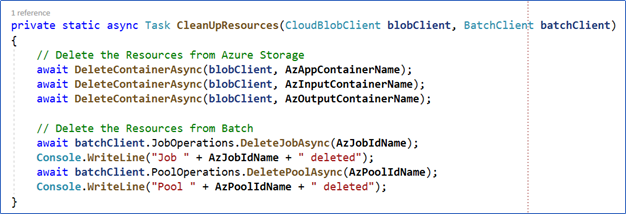
Figure 14. Clean up the Azure resources
Step 18 – The program run by the Tasks must be a Windows Console Application. Add a new Project in the Visual Studio Solution (called CreatePdf in the example). To create the PDFs, the example uses iText7, a CSharp library that allows you to create files of this type (https://github.com/itext/itext7-dotnet, it is a commercial product, but you can use the Open Source version for testing).
You need to install the iText7 NuGet in the project and add using directives to iText.Kernel.Pdf, iText.Layout, and iTextSharp.Layout.Element. Also, use the NuGet Windows.Azure.Storage to upload the files to the Azure Storage, and add using directives to Microsoft.WindowsAzure.Storage.Blob.
This program simply reads the XML file coming from SharePoint and creates a PDF file:
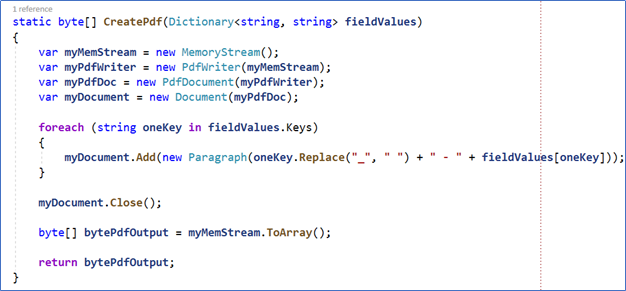
Figure 15. The creation of the PDF
The UploadFileToContainer uploads the created PDF file to the Azure Storage output blob:
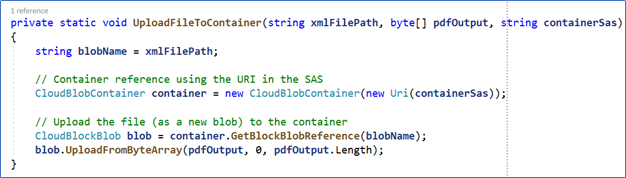
Figure 16. Upload of the PDF to the Azure Storage blob
Step 19 – Set the constant values at the beginning of the code with the real values which builds the complete solution. Run the program and observe the messages in the console:
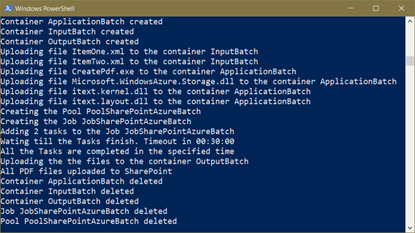
Figure 17. The output of the batch processing
When the application finishes working, the Azure resources are deleted and each item in the SharePoint List have two files as attachments (the XML and PDF files), containing the fields information:
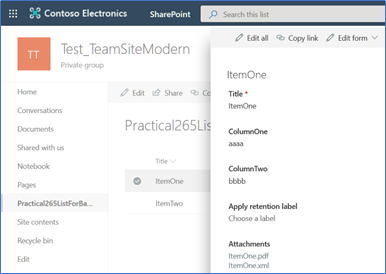
Figure 18. The result files in SharePoint
Conclusion
Within the many ways to use Azure services to complement the operation of SharePoint OnLine or OnPrem, Azure Batch enables you to move CPU and/or memory-intensive operations outside the SharePoint tenant to remote processes in Azure Virtual Machines.
Azure Batch works in conjunction with Azure Storage to receive the data files to be processed, executable files, and the results from processing. The system is scalable with virtually no calculation capacity and memory limits. The use cases are intelligent, going from relatively straightforward examples as the creation of PDFs as in the example, passing through extended engineering stress calculations for mechanisms and civil buildings, to time and resources expensive calculations for solving algorithms for physics or astronomical problem.

Gustavo Velez is a senior solutions architect specialized in integration of Microsoft software and Microsoft MVP Office Apps & Services. In his many years of experience developing and working with Windows and Office applications, Gustavo has given seminars/training in SharePoint as well as doing private consultancy work, and his articles can be found in many of the leading trade magazines in English, Dutch, German and Spanish. He is webmaster of http://www.gavd.net, the principal Spanish-language site dedicated to SharePoint. Gustavo is author of ten books about SharePoint, and founder and editor of CompartiMOSS (http://www.compartimoss.com), the reference magazine about Microsoft technologies for the Spanish-speaking community.
and
If you are looking for a cheap and genuine microsoft product key, 1-for-1 warranty from us for 1 year.
It will be available at the link: https://officerambo.com/shop/
Very pleased to serve you
Thank you :))
No comments:
Post a Comment